

What is it?
The LLM inference Plugin for Unreal provides simplified access to offline Large Language Model chat capabilities on Android devices. Under the hood the plugin is running Google Tensorflow Lite. A number of open source prebuilt models from Google Gemini are provided in the ThirdParty folder of the plugin, please use the models in accordance with the provided usage licences. You can also use any Tensorflow compatible LLM model with the plugin.
You can use existing LLM models or create your own LLM models and convert them to Tensorflow Lite format by following the instructions here.
By using LoRa files with the provided models you should be able to cover a large number of chat scenarios.
A converted Gemini LLM can be downloaded from https://gameplayintelligence.com/llm/gemma-2b-it-gpu-int4.bin.
How does it work?
The Plugin implements a GameInstance Subsystem that provides configuration options to a single LLM inference model. The Subsystem must be provided an inference model and built before it can be provided prompts. The results are then provided in callback delegates as they are processed.
The selected models are packaged with the Android binary during the Unreal cook process. The first time the application is run on the device these models must be unpacked and placed in a location where the LLM Inference plugin can access them. This is a blocking call and can result in extra loading time at the start of the application. These files are only copied on the first run of the application, subsequent app opens will not incur this loading cost.
Low Rank Adaptation (LoRa)
Low-Rank Adaptation (LoRA) for large language models allows you to customize the behavior of LLMs. For example perhaps you want your LLM to answer as a grumpy ogre or a medical doctor. A number of pre trained LoRa models for Google Gemini can be found here, you can convert them to Tensorflow lite format by following the instructions here. You can also train your own by following the instructions here.
A demonstration LoRa and its trained LLM can be downloaded from https://gameplayintelligence.com/llm/gemma-2b-it-text2sql.bin
https://gameplayintelligence.com/llm/gemma-2b-it-text2sql-lora.bin.
How to use it in game
There are six steps to successful in game LLM chat:
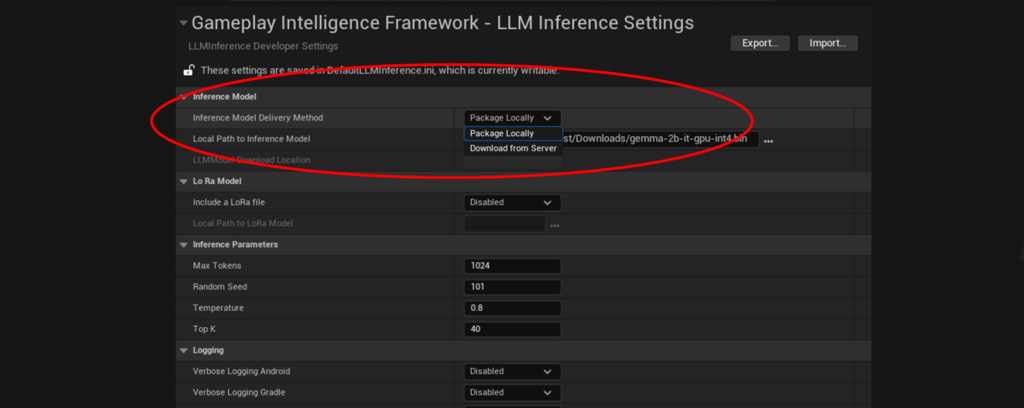
- Choose your LLM delivery method.
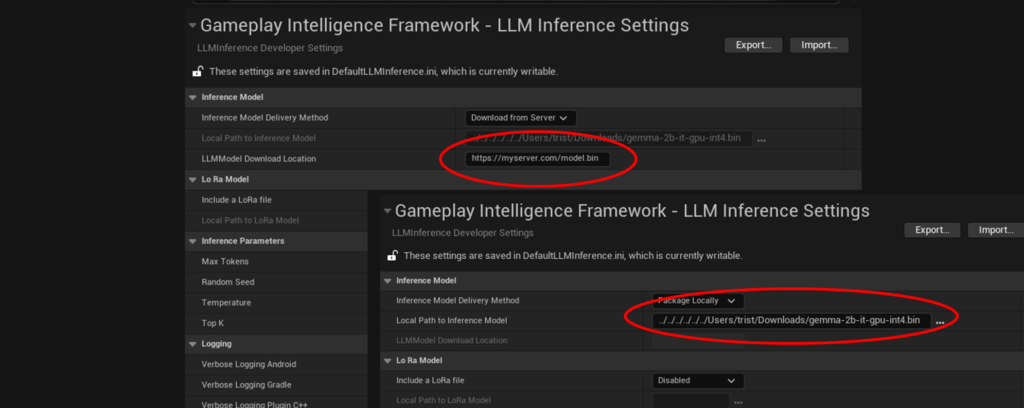
2. Set the inference model path or download URL depending on delivery method .
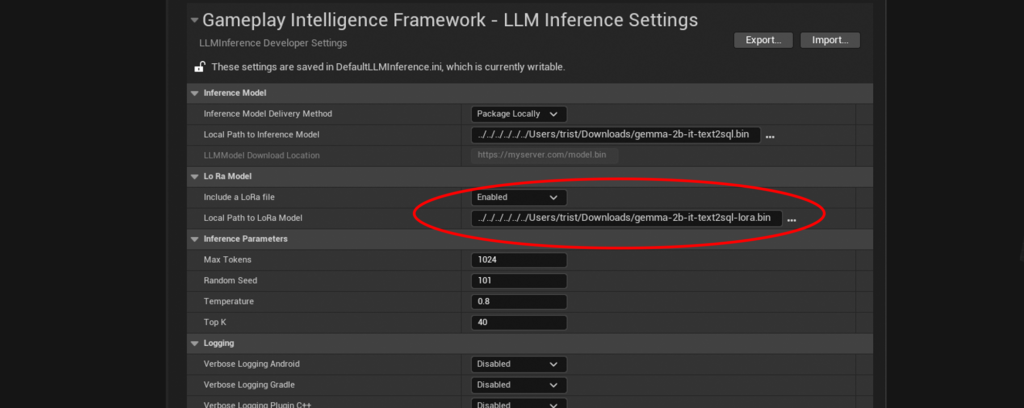
3. ( Optional ) Enable the LoRa and set the LoRa model path.
4. Build the inference model in Blueprint


5. Bind to the OnResponse and OnError callback events
5. Send prompts to the LLM

⚠️ Ensure that the LoRa Model is compatible with both Tensorflow Light and the chosen inference model, otherwise you will experience crashes on the device⚠️
Delivering the LLM File
The plugin provides two ways to deliver the LLM file to the device; package locally and download from server.
Package Locally
Used when the combined LLM file and LoRa file size is less than 2GB. Packages the LLM model into the assets folder of the .apk binary. The model will be copied out to a working directory on the first run of the application. The LLM file will not be copied if it already exists in the file system. You can monitor progress of the file copy by subscribing to the OnLLMFileCopyBegin, OnLLMFileCopyProgress and OnLLMFileCopyComplete events.
⚠️ If the combined LLM file and LoRa file size is over 2GB it can not be packaged with the Android .apk binary⚠️
Download from server
Used when the combined LLM file and LoRa file size is 2GB or more. The LLM will be downloaded from the URL set in the
LLM model location project setting field. The file must be publicly accessible and served over https. The LLM file will not be downloaded if it already exists in the file system. You can monitor progress of the file download by subscribing to the OnLLMFileDownloadBegin, OnLLMFileDownloadProgress and OnLLMFileDownloadComplete events.
⚠️ The download URL must be publicly accessible and delivered over https.⚠️
Inference Parameters
Parameters that manipulate the inference output are able to be set in the project settings.
| Top k | Sample from the k most likely next tokens at each step. Lower k focuses on higher probability tokens. Lower top-k also concentrates sampling on the highest probability tokens for each step. |
Temperature | Controls randomness, higher values increase diversity. Higher temperature will make outputs more random and diverse. |
RandomSeed | Controls the diversity of the output given the same input. |
MaxTokens | The maximum number of tokens to output during each generation step |
⚠️ Ensure that the values that you set make sense for the LoRa and inference models you have chosen otherwise you will experience crashes on the device⚠️
The Sample Map
The plugin includes a sample map that shows a very simple implementation of a chat bot in action. The map can be found in Content/Maps/SampleMap. Because Tensorflow relies on device hardware capability you must build the sample map out to a device for the chat functionality to work correctly.
Tips
- Running games on a mobile device is very resource intensive, running neural networks on a mobile device is also very resource intensive. For best results make sure to balance/disable the game resources ( e.g physics queries, update and tick loops) while the inference model is running.
- Visual feedback is important while the A.I. is thinking. Consider placing thought indicators on your character or User Interface.
- LLM responses can be hard to predict, experiment with the inference parameters and with the intended input.
- A prompt to create an NPC character could be as follows:
- ‘You are a Pirate character in a video game. Your objective is to tell the player to go to the dark forest. The player must make you happy before you will give the answer. You will be happy once the player asks you about your parrot. You will give hints about what makes you happy. You must not ask the player to do anything that is dangerous, unethical or unlawful.‘
FAQ
Is there a product road map?
Yes, the current development priorities are as follows:
- ☑️ Android Support
- 🟦 iOS support.
- 🟦 LoRa development and conversion tools.
- 🟦 Inference model training tools.
- 🟦 Windows support.
Unreal Packaging keeps failing?
You can enable detailed packaging log output by setting “Verbose Logging Gradle” to “Enabled”.
If Distribution packaging is enabled be sure to disable “Use AndroidFileServer” in “Project Settings->Plugins->AndroidFileServer”
If there is nothing obvious take a look at the known issues below and feel free to contact us through the contact form here.
Are there any known issues?
Following are some gotcha‘s to be aware of:
* Error checking could be better – There are some runtime errors that the engine will still package that will cause the app to crash when run on the device.
* Unreal will still package a build if no inference model is set which will result in a runtime error on the device.
* There are no clearly defined device profiles for inference and LoRa models. This means that you must select the correct cpu, gpu and hardware capable matches for the models running on the device.
* The inference and LoRa Model files will be copied from the packaged application to local file storage on the device when first run, this results in a startup delay. This is intended to be fixed in later versions.
* The topK and temperature must be set to reasonable value for the inference and LoRa models, otherwise the device may crash.
* There is currently no way to stop the inference output once it has started.
* You must disable the Android File System module from the project settings when building for distribution.
* External storage permissions must be granted. You can enable these by ticking the ‘Use ExternalFilesDir for Unreal Game Files’ checkbox in the ‘Platforms->Android->APK Packaging’ section of the project settings.
How can I get support or report a bug or feature request?
You can report a bug using our contact form here. Feature requests are always welcome : )
My app keeps crashing on device?
If the app has packaged successfully but is crashing when running on the device the first step is to view the Android logs through Android Studio or something similar. You can filter on the tags “Unreal”, “LLMInference” and “gameplayintelligence” to find issues. Make sure that you have set “Verbose Logging Android” to “Enabled”.
Other things that can cause crashes are :
- Running a CPU model on an unsupported device
- Failing to set an inference model path in the project settings.
- The LoRa model is not compatible with the inference model